


The AX Audit is the free check we run against any public URL to score how prepared a site is for AI agents and crawlers — ChatGPT browsing, Perplexity, Bing Copilot, Claude with web search, and the rest. We've never published the rubric behind it, which made the score feel like a black box. This post is the rubric. Six dimensions, transparent weights, the things we deliberately don't score, and the failure modes we see most often.
The shift is bigger than "add JSON-LD" advice you'll see on most SEO blogs. AI agents don't read pages the way Googlebot does — they pull, parse, sometimes execute structured payloads, and increasingly speak structured protocols like MCP. A site that scores 95 on classical SEO tools can score 40 on AX, because the things that matter to a crawler-rendering-CSS are not the things that matter to an agent trying to act on a user's behalf.
The six AX Audit dimensions and their weights
| # | Dimension | Weight | What it measures |
|---|---|---|---|
| 1 | Crawlability | 20 | robots.txt rules for AI user-agents (GPTBot, PerplexityBot, ClaudeBot, etc.), response codes, redirect chains, render-blocking issues that hide content from non-JS clients. |
| 2 | Discoverability | 18 | Sitemap presence and freshness, llms.txt, canonical signals, internal linking depth, IndexNow + AI-specific submission endpoints. |
| 3 | Structured data | 18 | JSON-LD coverage (Article, FAQPage, HowTo, SoftwareApplication, Product), validity, alignment with the visible content, presence of entity identifiers (sameAs). |
| 4 | Content quality | 16 | First-party signals: bylines, dates, original methodology, primary sources cited. The intermediary-content penalty from the March 2026 core update lives here. |
| 5 | Agent interaction | 18 | MCP server presence, public API discoverability, structured form schemas, and whether an agent can complete a primary task on the site without a human in the loop. |
| 6 | Security & trust | 10 | HTTPS, valid certificates, security headers (HSTS, CSP), privacy policy presence, terms-of-service that don't blanket-prohibit AI scraping for legitimate use. |
| — | Total | 100 | Anchored at 100 so grade bands stay readable: A 90+, B 80–89, C 70–79, D 60–69, F below 60. |
Why a separate score from classical SEO
Classical SEO tools (Lighthouse, Ahrefs site audit, Screaming Frog) optimise for one consumer: a search-engine crawler that renders pages, builds an index, and ranks results for a query. They were built for the SERP era. They're still useful, but they don't tell you what an AI agent — sent by a user to actually accomplish something on your site — sees and can do.
Three behaviours diverge: agents respect (or ignore) robots.txt rules specific to AI user-agents, which classical SEO tools don't check; agents look for structured task surfaces (MCP, public APIs, form schemas) that classical SEO doesn't measure; and agents heavily weight first-party content signals over backlink graphs, which classical SEO over-weights. A site that ranks #1 on Google for a long-tail query can be invisible to ChatGPT browsing because its robots.txt blocks GPTBot — and no classical audit will tell you that.
Dimension 1: Crawlability — the failure mode 70% of sites have
Crawlability sounds boring and is the single most common reason a site flunks AX. The pattern: a site copies a robots.txt template from 2019 (or worse, lets a CDN auto-generate one) that allows Googlebot but blocks every AI user-agent by default. The site owner doesn't realise this until they notice their content stops appearing in ChatGPT and Perplexity answers.
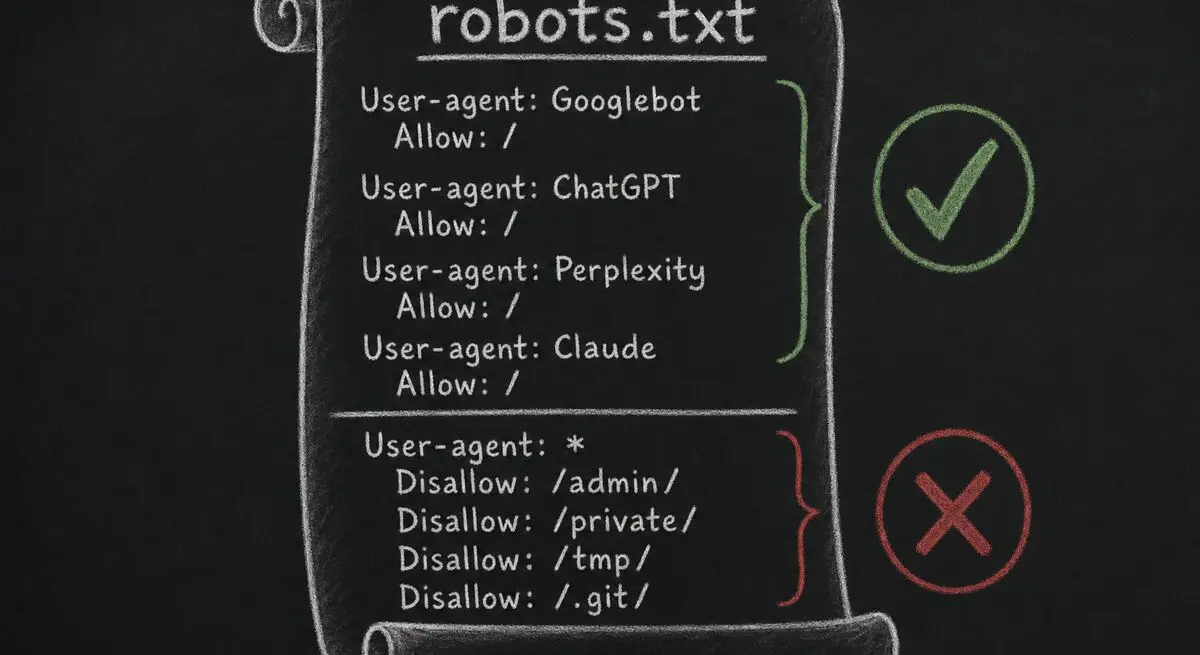
We check seven user-agents specifically: GPTBot, ChatGPT-User, PerplexityBot, Perplexity-User, ClaudeBot, anthropic-ai, and Bingbot. A site that allows all seven scores full marks. A site that allows Googlebot but disallows GPTBot loses 8 points, because that's the single highest-cost line in a robots.txt file in 2026 — that one decision is what determines whether your content is read by 700M ChatGPT users.
The other half of crawlability is render-blocking: pages that require JavaScript execution to surface their main content, or that gate content behind interaction. AI crawlers vary in their JS execution capability — GPTBot does some, Perplexity does more, others none. We score against the lowest-common-denominator: a page should expose its primary content in server-rendered HTML.
Dimensions 2 + 3: Discoverability and structured data
Discoverability is sitemap and llms.txt territory. Sitemaps you already know — keep them under 50,000 URLs per file, segment by content type, refresh on publish. The newer signal is llms.txt, a flat-file convention that lets you tell AI agents which URLs to prioritise reading. Few sites have one. The ones that do tend to rank higher in AI-grounded answers because the agents have a curated entry point instead of crawling the long tail.
Structured data is JSON-LD coverage — the schema.org types that turn a paragraph of prose into a machine-readable claim. We check for Article, FAQPage, HowTo, SoftwareApplication, and Product where each is appropriate, and we check that the JSON-LD agrees with the visible page (a common bug: the article body says "updated 2026-04-15" and the JSON-LD says "2024-09-01" because the schema is templated and the date isn't injected). We also flag missing sameAs entity links — they're cheap to add and they let agents disambiguate which "Dashform" or "Acme Corp" you mean. For an example of how a methodology document combines structured tables with original prose, see our form-builder evaluation rubric.
Dimension 4: Content quality (and the intermediary penalty)
Content quality is where Google's March 2026 core update lives in our rubric. The update demoted "intermediary content" — pages that aggregate, summarise, or template-fill information without adding first-party judgement. Comparison directories, programmatic SEO matrices, listicles assembled from press releases. The pattern is reproducible by an LLM in seconds, and the search ecosystem now treats it as low-value.
We score four content-quality signals: (a) is there a real byline with a real reviewer, not an anonymous "editorial team" badge; (b) is the page dated and is that date in the JSON-LD; (c) does the page cite primary sources for the claims it makes; and (d) is the structural template recognisable as something a human author chose for this topic, not the same template applied to 800 pages?
Sites that score high on content quality almost always also rank high on AX overall. Sites that score low usually have the same fix: name the author, anchor the date to publish time, cite the sources, and make the structure of each page reflect the topic instead of a one-size-fits-all template. The work is editorial, not technical.
Dimension 5: Agent interaction — the new frontier
Agent interaction is the dimension most sites haven't thought about. Classical SEO ends at "can the page be read?" Agent interaction asks the harder question: "can a third-party agent, sent by a user, complete a task on this site?" That task might be filling a form, booking an appointment, comparing a product, or pulling a structured payload.
We score three sub-signals. MCP server presence — does the site expose a Model Context Protocol endpoint that an agent can speak? Public API discoverability — is there a documented API at a stable URL, with auth that an agent can negotiate? Structured form schemas — for sites with primary forms (signup, contact, product configuration), are the forms machine-readable so an agent can submit them on a respondent's behalf? The third sub-signal is where Dashform's own bias shows: we built the company around the idea that forms should be agent-fillable, and most of the form-builder category is not.
This is also the dimension where scores will move the most over the next 12–18 months. In 2024, almost no site exposed an MCP server. In 2026, the percentage is small but rising fast — and the early adopters are starting to win in agent-driven traffic. We expect this dimension's weight to grow in our next rubric revision (see the cadence note at the bottom).
Dimension 6: Security and trust
Security and trust is the lowest-weight dimension because most sites get most of it right by default. HTTPS, valid certificate, baseline security headers — these are largely a CDN configuration question. We still flag the failures because they're cheap to fix and because agents (especially the more conservative ones) will refuse to interact with a site whose certificate has expired, the same way a careful user will.
The judgement call here is on terms-of-service and privacy policy. We do not penalise sites for charging for content or gating it behind login — that's a legitimate business decision. We do penalise terms that blanket-prohibit AI scraping for any purpose, because that's an opt-out of the entire AI ecosystem and it should be a deliberate choice, not a copy-pasted clause. If your site genuinely doesn't want to be in AI answers, that's fine — the AX score will reflect that, and your readers can interpret it.
What we deliberately don't score
Three things show up in other AI-readiness checks that we've decided not to weight, and we want to be specific about why:
Page speed and Core Web Vitals. Classical SEO tools score these and they matter for human users. They don't matter for most AI agents — agents have different patience profiles than humans, and a 4-second LCP that's a real penalty for a user is roughly nothing for an agent that's already spending 30 seconds on the LLM call. We surface CWV as a sub-note in the report but we don't fold it into the AX score.
Backlink count. Backlinks were the dominant Google ranking signal for two decades. AI grounding works differently — agents weight first-party content signals (originality, freshness, citations) far more than they weight off-site link graphs. A site with 10,000 backlinks and copy-paste content scores worse on AX than a site with 50 backlinks and a real bylined methodology page.
Mobile-friendliness. Agents don't have viewports. Mobile rendering matters for human users; we don't grade it as part of AX because it doesn't change what an agent can read or do.

Cadence and updates
We re-score the AX rubric quarterly. The next scheduled revision is August 2026. Expected changes for that pass:
Splitting agent interaction into MCP, API, and form-schema as separate sub-dimensions. Right now they're rolled into one 18-point weight; the sub-signals are diverging and deserve separate scoring.
Adding a freshness penalty to discoverability for sitemaps with last-modified dates older than 12 months. Stale sitemaps signal that the site itself is stale, and agents are starting to weight this.
Re-weighting structured data downward as JSON-LD becomes universal — the ceiling has moved up, so the relative value of having JSON-LD at all is dropping. Quality of JSON-LD will continue to matter.
Frequently Asked Questions
Why is the total weight 100 if your form-builder rubric uses 84?
The form-builder rubric is for evaluating products against each other; the open total leaves room to add tools and criteria over time. The AX Audit is a measurement against an absolute target — "is this site ready for the AI ecosystem in 2026" — so a 100-point scale produces readable grade bands (A, B, C, D, F) that map to letter-grade intuitions.
Does AX Audit work for sites in any language?
Yes — most of the dimensions are language-agnostic (robots.txt, JSON-LD validity, MCP presence, certificate validity). Content quality scoring uses heuristics that work across languages, but the byline detection is currently strongest in English, French, German, Spanish, Portuguese, and Chinese; other languages may produce slightly less accurate sub-scores until we expand coverage.
How is this different from Lighthouse or Ahrefs?
Lighthouse and Ahrefs are excellent for classical SEO and human-user experience. AX Audit measures something they don't: how prepared the site is for AI agents and AI-grounded search. We recommend running both — they answer different questions, and a site can score 95 on Lighthouse and 50 on AX (or vice versa).
My site uses Cloudflare's bot management — does that affect the audit?
Maybe. Cloudflare's AI bot blocking is enabled by default on many plans and silently drops requests from GPTBot, PerplexityBot, ClaudeBot, etc. before they reach your site. We detect this when our crawler is challenged or rate-limited; the audit report will flag it as a crawlability issue with a recommendation to allow-list the AI user-agents you want to be readable by.
Do you store the URLs people audit?
Yes — we store the URL and the audit result so users can return to a previous report and compare against later runs. We don't store credentials, request headers, or any private content. The audit itself only fetches public pages with a clearly identified user-agent.
How often should I re-run the audit?
Quarterly is enough for most sites. Re-run after any of: changing robots.txt, deploying a new sitemap, adding JSON-LD, changing the site's main framework (e.g., migrating from a SPA to SSR), or whenever we publish a new rubric revision (we'll mention it in the changelog at the top of this post).
Can I get the report as a PDF or share it with my team?
Each audit report has a permanent URL — share that. PDF export is on the roadmap for late 2026; we held off because PDFs go stale fast and we'd rather you re-run the live audit than circulate a frozen number.
What's a "good" AX score?
80+ (B grade) is strong — your site is in the top quartile of what we audit. 90+ (A) is rare and almost always reflects deliberate work, not luck. Below 60 (F) means there's at least one structural blocker (robots.txt is the usual culprit) that's worth fixing before any of the other dimensions matter.
Conclusion
If a site's AX Audit produces a number, this rubric is the receipt. Six dimensions, transparent weights, the things we don't score, the cases where the answer is editorial rather than technical. We'd rather you read this and then run the audit than the other way around. The audit is free, no account required, and runs against any public URL — your own site, a competitor's, a candidate vendor's during procurement.





